Zyphra redefine la eficiencia en modelos visión-lenguaje con Zamba2-VL
Zyphra ha lanzado Zamba2-VL, una familia de modelos de visión-lenguaje de código abierto (1.2B, 2.7B, 7B parámetros) que integran arquitecturas híbridas Mamba2 state-space y Transformer. Esta combinación reduce el tiempo de generación del primer token ('time-to-first-token') en aproximadamente un orden de magnitud, manteniendo un rendimiento competitivo frente a modelos Transformer puros, bajo licencia Apache 2.0.
Por Carlos "Emérito" López Lovera•12 jun 2026•4 min lectura
Puntos Clave
- Zamba2-VL introduce una arquitectura híbrida Mamba2-Transformer, optimizando la eficiencia de inferencia en modelos de visión-lenguaje.
- La innovación principal radica en la reducción del 'time-to-first-token' en aproximadamente un orden de magnitud, crucial para aplicaciones interactivas y en tiempo real.
- La disponibilidad bajo licencia Apache 2.0 facilita la adopción y el desarrollo en el ecosistema de IA, democratizando el acceso a modelos de alto rendimiento y eficiencia.
Análisis de la arquitectura híbrida Mamba2-Transformer
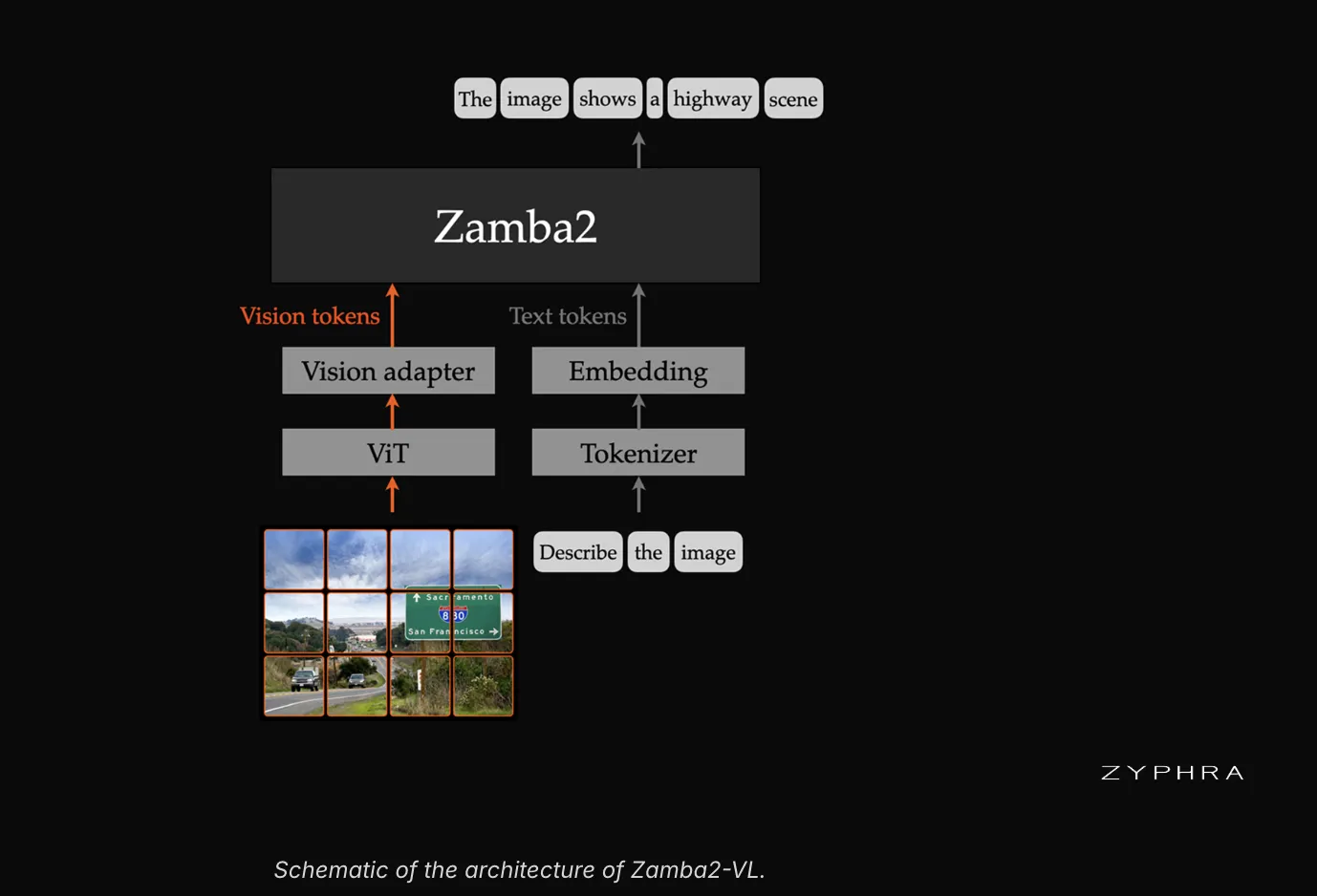
La reciente publicación de Zamba2-VL por Zyphra representa una evolución en el diseño de modelos de visión-lenguaje (VLM). Esta familia de modelos, disponible en configuraciones de 1.2B, 2.7B y 7B parámetros, integra una arquitectura híbrida que combina el modelo de espacio de estados Mamba2 con el paradigma Transformer. Esta fusión aborda limitaciones inherentes a las arquitecturas puras dominantes en el campo de la inteligencia artificial generativa.
Históricamente, los modelos Transformer han sido la base para avances significativos en procesamiento de lenguaje natural y visión, gracias a su mecanismo de autoatención que permite capturar dependencias a largo alcance. No obstante, la complejidad computacional de la autoatención escala cuadráticamente con la longitud de la secuencia, lo que impone desafíos en términos de memoria y tiempo de inferencia, especialmente para secuencias extensas o despliegues en tiempo real. Este factor ha sido un cuello de botella para la escalabilidad y la eficiencia operativa.
Mamba2, por otro lado, es una iteración de los modelos de espacio de estados (SSM) que ofrece una alternativa con una complejidad computacional que escala linealmente con la longitud de la secuencia. Los SSMs han mostrado promesas en eficiencia, pero versiones anteriores carecían de la capacidad de modelar contextos complejos y dinámicos de manera comparable a los Transformers. Mamba2 mejora esto, ofreciendo una eficiencia superior en inferencia y un menor consumo de memoria, sin sacrificar significativamente la capacidad de representación en diversas tareas.
La estrategia de Zyphra con Zamba2-VL capitaliza las fortalezas de ambas arquitecturas. Es plausible que la parte Transformer se encargue de la codificación inicial de características o la atención global, mientras que Mamba2 se optimiza para la generación secuencial de tokens. Esta sinergia permite que Zamba2-VL mantenga un rendimiento competitivo en tareas de visión-lenguaje, al mismo tiempo que logra una reducción significativa en el 'time-to-first-token'.
Implicaciones técnicas y económicas de la eficiencia en inferencia
La reducción del 'time-to-first-token' en aproximadamente un orden de magnitud es una métrica de rendimiento crítica. En aplicaciones interactivas, como asistentes virtuales, sistemas de subtitulado en tiempo real o plataformas de generación de contenido multimodal, la latencia inicial es un factor determinante para la experiencia del usuario. Una respuesta más rápida mejora la fluidez de la interacción y la percepción de la inmediatez, lo cual es fundamental para la adopción y retención de usuarios.
Desde una perspectiva técnica, esta mejora implica una optimización sustancial en los recursos computacionales requeridos para la inferencia. Menos tiempo de cómputo por token se traduce directamente en un menor consumo de energía y una utilización más eficiente de la infraestructura de hardware (GPUs). Para empresas que despliegan modelos de IA a gran escala, esto puede resultar en reducciones significativas en los costos operativos. La capacidad de procesar más solicitudes por unidad de tiempo con la misma infraestructura o la necesidad de menos hardware para el mismo volumen de trabajo, tiene un impacto económico directo en el retorno de la inversión (ROI) de las implementaciones de IA.
La disponibilidad de Zamba2-VL bajo la licencia Apache 2.0 es otro factor económico y técnico relevante. El carácter de código abierto facilita la adopción por parte de la comunidad de investigación y desarrollo, así como por empresas de menor envergadura que podrían no tener los recursos para desarrollar modelos desde cero o licenciar soluciones propietarias costosas. Esto fomenta la innovación, permite la personalización y la integración en diversos productos y servicios, y acelera el ciclo de vida de desarrollo de aplicaciones basadas en VLM.
La competitividad de Zamba2-VL frente a VLMs basados exclusivamente en Transformer, combinada con su eficiencia superior en inferencia, posiciona a Zyphra como un actor relevante en el espacio de los modelos fundacionales. Podría incentivar a otros desarrolladores a explorar arquitecturas híbridas o a priorizar la eficiencia computacional en sus diseños, alejándose del paradigma exclusivo de Transformer para ciertos casos de uso.
La evolución hacia arquitecturas híbridas como Zamba2-VL sugiere una tendencia en la industria de la IA hacia la optimización del rendimiento en inferencia. La capacidad de reducir drásticamente el 'time-to-first-token' sin comprometer la calidad del resultado final es un punto de control fundamental para la viabilidad económica y la escalabilidad de la inteligencia artificial generativa en entornos de producción y aplicaciones en tiempo real.
📖 Glosario de términos
❓ Preguntas Frecuentes
¿Qué es Zamba2-VL?
Zamba2-VL es una familia de modelos de visión-lenguaje desarrollados por Zyphra, que utiliza una arquitectura híbrida Mamba2-Transformer para mejorar la eficiencia de inferencia.
¿Cuál es la principal ventaja de Zamba2-VL?
La principal ventaja es una reducción significativa, de aproximadamente un orden de magnitud, en el 'time-to-first-token', lo que resulta en una mayor velocidad de respuesta para el usuario en aplicaciones interactivas.
¿Bajo qué licencia se distribuye Zamba2-VL?
Zamba2-VL se distribuye bajo la licencia Apache 2.0, lo que lo convierte en un modelo de código abierto accesible para la comunidad de desarrolladores y empresas.
Artículos relacionados


Apoya nuestro periodismo independiente: Si decides invertir en criptomonedas, considera usar nuestro enlace de afiliado de Binance. Tú recibes un bono de bienvenida y nosotros una pequeña comisión.
Aviso: Este contenido no es consejo financiero. Haz tu propia investigación antes de invertir.
