Zyphra Redefines Efficiency in Vision-Language Models with Zamba2-VL
Zyphra introduces Zamba2-VL, an open-source family of hybrid Mamba2 state-space and Transformer vision-language models (1.2B, 2.7B, 7B parameters). Zamba2-VL significantly reduces 'time-to-first-token' by an order of magnitude while maintaining competitive performance against pure Transformer models, released under an Apache 2.0 license.
By Carlos "Emérito" López Lovera•12 jun 2026•3 min read
Key Takeaways
- Zamba2-VL introduces a hybrid Mamba2-Transformer architecture, optimizing inference efficiency in vision-language models.
- The primary innovation lies in reducing the 'time-to-first-token' by approximately an order of magnitude, crucial for interactive and real-time applications.
- Its availability under the Apache 2.0 license facilitates adoption and development within the AI ecosystem, democratizing access to high-performance and efficient models.
Analysis of the Hybrid Mamba2-Transformer Architecture
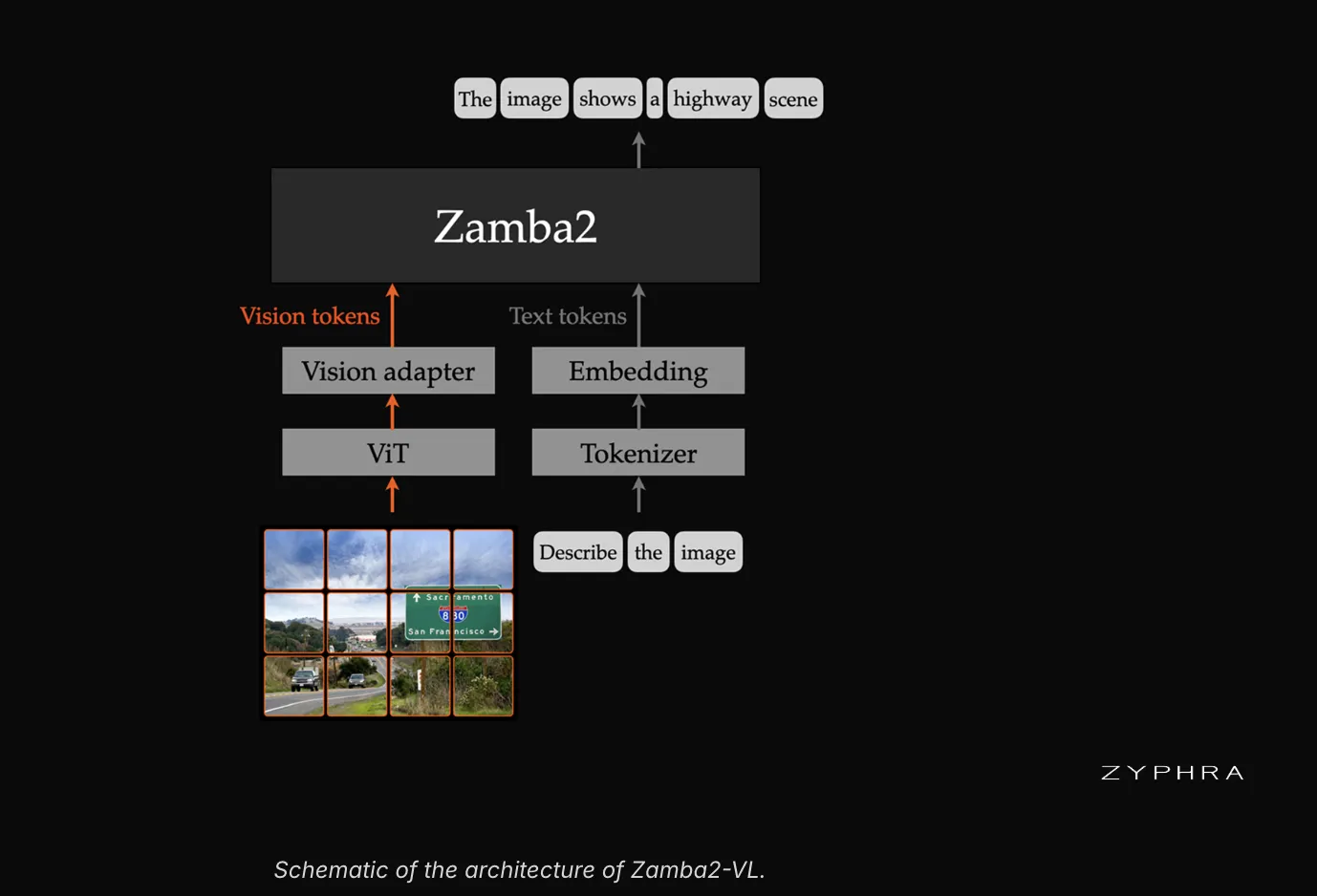
Zyphra's recent release of Zamba2-VL marks an evolution in the design of vision-language models (VLMs). This family of models, available in 1.2B, 2.7B, and 7B parameter configurations, integrates a hybrid architecture combining the Mamba2 state-space model with the Transformer paradigm. This fusion addresses limitations inherent in the pure architectures dominating the field of generative artificial intelligence.
Historically, Transformer models have been the foundation for significant advancements in natural language processing and vision, thanks to their self-attention mechanism that allows for capturing long-range dependencies. However, the computational complexity of self-attention scales quadratically with sequence length, posing challenges in terms of memory and inference time, especially for extensive sequences or real-time deployments. This factor has been a bottleneck for scalability and operational efficiency.
Mamba2, on the other hand, is an iteration of state-space models (SSMs) that offers an alternative with computational complexity scaling linearly with sequence length. SSMs have shown promise in efficiency, but previous versions lacked the ability to model complex and dynamic contexts comparably to Transformers. Mamba2 improves upon this, offering superior inference efficiency and lower memory consumption, without significantly sacrificing representational capacity across various tasks.
Zyphra's strategy with Zamba2-VL capitalizes on the strengths of both architectures. It is plausible that the Transformer component handles initial feature encoding or global attention, while Mamba2 is optimized for sequential token generation. This synergy allows Zamba2-VL to maintain competitive performance in vision-language tasks while achieving a significant reduction in 'time-to-first-token'.
Technical and Economic Implications of Inference Efficiency
The reduction of 'time-to-first-token' by approximately an order of magnitude is a critical performance metric. In interactive applications such as virtual assistants, real-time subtitling systems, or multimodal content generation platforms, initial latency is a determining factor for user experience. A faster response improves interaction fluidity and the perception of immediacy, which is fundamental for user adoption and retention.
From a technical perspective, this improvement implies a substantial optimization in the computational resources required for inference. Less computation time per token directly translates into lower energy consumption and more efficient utilization of hardware infrastructure (GPUs). For companies deploying AI models at scale, this can result in significant reductions in operational costs. The ability to process more requests per unit of time with the same infrastructure, or the need for less hardware for the same workload, has a direct economic impact on the return on investment (ROI) of AI implementations.
The availability of Zamba2-VL under the Apache 2.0 license is another relevant economic and technical factor. Its open-source nature facilitates adoption by the research and development community, as well as by smaller companies that might lack the resources to develop models from scratch or license expensive proprietary solutions. This fosters innovation, allows for customization and integration into various products and services, and accelerates the development lifecycle of VLM-based applications.
Zamba2-VL's competitiveness against exclusively Transformer-based VLMs, combined with its superior inference efficiency, positions Zyphra as a relevant player in the foundational models space. It could encourage other developers to explore hybrid architectures or prioritize computational efficiency in their designs, moving away from the exclusive Transformer paradigm for certain use cases.
The evolution towards hybrid architectures like Zamba2-VL suggests a trend in the AI industry towards optimizing inference performance. The ability to drastically reduce 'time-to-first-token' without compromising final output quality is a fundamental checkpoint for the economic viability and scalability of generative artificial intelligence in production environments and real-time applications.
📖 Key Terms Glossary
❓ Frequently Asked Questions
What is Zamba2-VL?
Zamba2-VL is a family of vision-language models developed by Zyphra, utilizing a hybrid Mamba2-Transformer architecture to enhance inference efficiency.
What is the main advantage of Zamba2-VL?
The main advantage is a significant reduction, by approximately an order of magnitude, in 'time-to-first-token,' leading to faster user response times in interactive applications.
Under what license is Zamba2-VL distributed?
Zamba2-VL is distributed under the Apache 2.0 license, making it an open-source model accessible to the developer community and businesses.
Support independent journalism 💸
The crypto ecosystem is volatile. If you decide to invest, do it safely using our affiliate links in the most trusted exchanges. You get a welcome bonus and we get a small commission.
Disclaimer: This content is not financial advice. Do your own research before investing.


