Tokenization Drift: A Silent Threat to AI Reliability
Artificial intelligence models can experience unexpected performance degradation, even when input data, pipelines, and logic remain unchanged. This phenomenon, known as tokenization drift, arises from subtle inconsistencies in how text is converted into token identifiers, profoundly affecting model inference.
By Carlos "Emérito" López Lovera•3 may 2026•3 min read
Key Takeaways
- Tokenization drift occurs when small variations in text input format alter token IDs, even if the semantic content is similar.
- This issue is challenging to diagnose because it doesn't involve changes in raw data, model logic, or the processing pipeline, but rather in the preprocessing phase.
- The reliability of AI systems is compromised, necessitating more sophisticated monitoring of the tokenization phase and robust preprocessing strategies.
In the realm of artificial intelligence, the promise of autonomous and predictive systems has driven unprecedented investment. However, the reliability and consistency of these models, especially language-based ones, are not without subtle yet pernicious challenges. An emerging phenomenon, tokenization drift, illustrates how the underlying infrastructure of AI models can undermine their performance in unexpected ways, even when input data, processing pipelines, and model logic apparently remain unchanged.
The Insidious Nature of Tokenization Drift
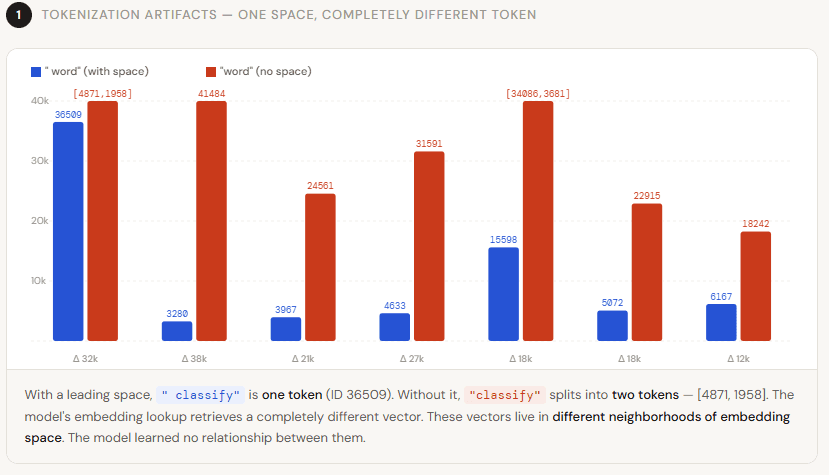
Before a Large Language Model (LLM) can process text, it must be converted into a sequence of numerical identifiers, a process known as tokenization. This critical step transforms words, subwords, or characters into discrete units that the model can understand. Tokenization drift occurs when minimal variations in the format of a text input—a difference in spacing, capitalization, or the presence of special characters—result in the generation of a different set of tokens or token IDs. For instance, 'Apple' and 'apple' might be tokenized identically at one point but differently at another, or an extra space could alter the token sequence of an entire phrase. The model, receiving a numerical representation different from what it expects, may interpret the input incorrectly, leading to performance degradation or inconsistent results.
Beyond Data: The Preprocessing Blind Spot
The inherent difficulty in detecting tokenization drift lies in its location within the processing chain. Traditional ML monitoring tools typically focus on raw data quality or final model performance. However, tokenization drift is not a change in the data itself, but in its internal representation. Engineering teams might observe an inexplicable drop in model accuracy or consistency, yet upon reviewing input data and model logic, they find no anomalies. This creates a critical blind spot, where the root cause resides in how tokenization algorithms, often third-party libraries or predefined components, handle subtly different inputs over time or across environments.
Operational and Strategic Implications
The existence of tokenization drift has profound implications for the reliability and auditability of AI systems. Trust in these models erodes when their behavior becomes erratic and unpredictable without an obvious cause. Operationally, diagnosing and mitigating this issue requires granular visibility into the preprocessing stage, which many current MLOps pipelines do not natively offer. Strategically, businesses relying on AI for critical decision-making, from customer service to fraud detection, face significant risks if their models operate with compromised accuracy due to such elusive factors.
The need for robust monitoring that encompasses not only data and model performance but also the intrinsic details of their internal representation becomes imperative. As AI systems integrate more deeply into enterprise infrastructure, understanding and controlling phenomena like tokenization drift will be fundamental to ensuring their stability and, ultimately, their long-term value in the technological landscape.
📖 Key Terms Glossary
❓ Frequently Asked Questions
What is tokenization drift?
It is an issue in AI models where minimal changes in text input format cause different tokens to be generated, degrading model performance without altering the underlying data or logic.
Why is tokenization drift difficult to detect?
Its detection is complex because traditional monitoring tools focus on data quality or model performance, overlooking subtle inconsistencies in the preprocessing phase, specifically in tokenization.
How does tokenization drift affect AI models?
It affects the model's ability to correctly interpret inputs, which can lead to erroneous predictions, inconsistent responses, and an overall decrease in reliability and accuracy over time.
Support independent journalism 💸
The crypto ecosystem is volatile. If you decide to invest, do it safely using our affiliate links in the most trusted exchanges. You get a welcome bonus and we get a small commission.
Disclaimer: This content is not financial advice. Do your own research before investing.