Inworld AI Launches Realtime TTS-2: A Closed-Loop Voice Model That Adapts to Human Speech
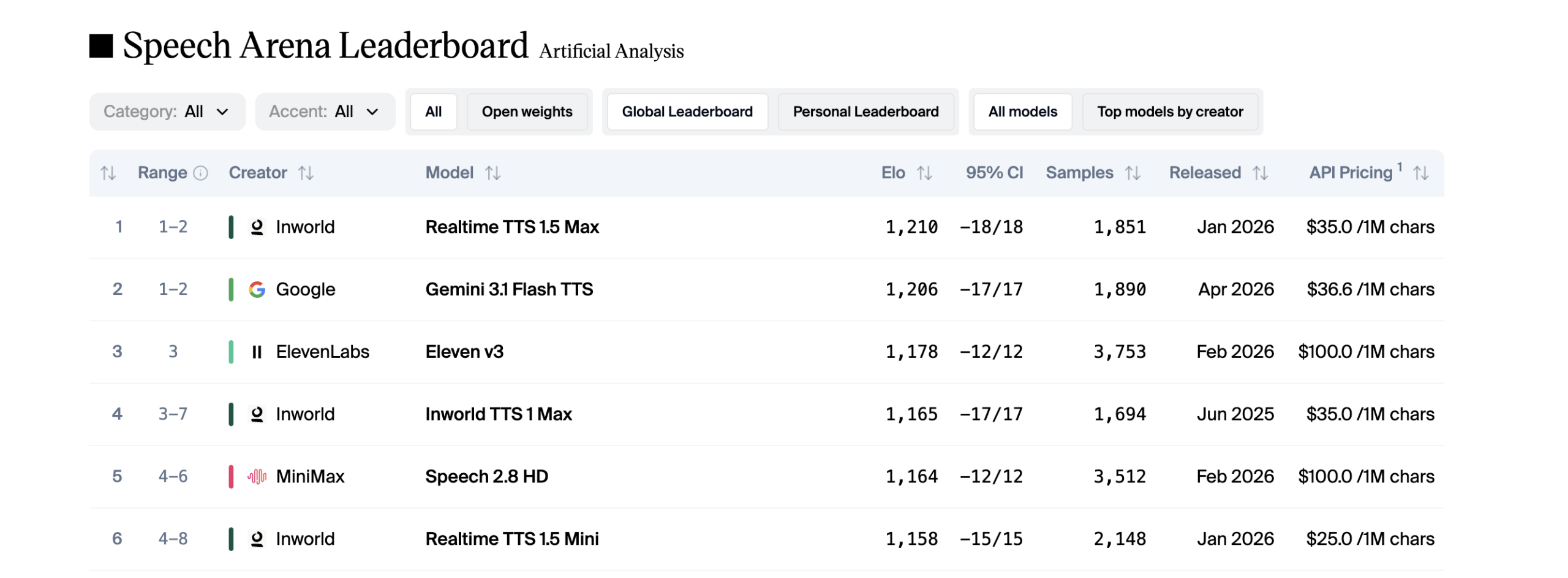
Inworld AI has unveiled Realtime TTS-2, a speech synthesis model that processes the full audio context, not just transcripts, to generate dynamic and adaptive responses. This architectural shift enhances the naturalness and interactivity of real-time conversational AI agents, marking an evolution in human-machine interaction.
By Carlos "Emérito" López Lovera•6 may 2026•4 min read
Key Takeaways
- Realtime TTS-2 utilizes the full audio context of the speaker for voice synthesis, moving beyond exclusive reliance on text transcriptions.
- Its 'closed-loop' architecture enables dynamic, real-time adaptation to the style, pace, and intonation of human conversation.
- This innovation enhances the naturalness of AI agents, with direct implications for immersion in gaming, efficiency in customer service, and the sophistication of virtual assistants.
Inworld AI, an entity specializing in conversational artificial intelligence, has announced the launch of its Realtime TTS-2 model. This new iteration represents an evolution in speech synthesis (TTS) by integrating a closed-loop approach that conditions voice generation not only on text transcriptions but on the full audio context of an interaction. This development modifies the standard architecture of TTS systems and their applications in AI agents.
Technical Analysis of Inworld AI's Realtime TTS-2
The core capability of Realtime TTS-2 lies in its "full audio context" processing. Historically, TTS models have predominantly operated on textual input, converting characters or phonemes into sound waves. While recent advancements in neural TTS models have allowed for greater naturalness and the replication of specific voice styles, most still operate unidirectionally: text-to-speech. Inworld AI's model introduces a processing layer that analyzes prosodic elements such as intonation, rhythm, pauses, and emphasis from the human speaker in real-time. This contextual information is integrated into the AI agent's voice generation process, allowing the synthesized response to reflect and adapt to the style and flow of the ongoing conversation.
The term "closed loop" is fundamental here. In systems engineering, a closed loop implies a feedback mechanism where the system's output is fed back into the input to adjust its behavior. This contrasts with open-loop systems, where the output does not directly influence the input. In this context, the voice generated by the AI agent, as well as the voice of the human interlocutor, form part of a continuous cycle of analysis and synthesis. The implementation of a closed loop in voice synthesis allows for dynamic adaptation, resulting in a more fluid and less robotic conversational experience. The system can, for example, adjust its speaking speed or tone in response to the user's speed or tone, creating a more empathetic and natural interaction.
Architectural and Operational Implications
The adoption of an architecture that considers the full audio context represents a significant shift. Previous models, even the most advanced ones, often struggled with inflexibility in the middle of a dynamic conversation. An AI agent that only converts text to speech cannot mimic the natural cadence of a person who adjusts their speech based on the interlocutor's pauses or exclamations. Realtime TTS-2 addresses this by allowing the AI agent to not only "understand" what is said (via ASR, automatic speech recognition) but also "how" it is said, and modulate its own vocal response accordingly.
From an operational perspective, this reduces cognitive dissonance for the user. Interactions with AI are often hampered by monotone or unadaptive voices, which can lead to frustration or a sense of artificiality. By emulating more complex human speech patterns, Inworld AI's technology seeks to minimize this friction. This has direct implications for the "presence" of AI agents in virtual environments, such as metaverses, where immersion is a critical factor. The ability of a non-player character (NPC) in a video game to respond with a voice that modulates in real-time according to player interaction increases the environment's credibility.
Economic Impact and Affected Sectors
The economic ramifications of this technology are multifaceted. In the gaming sector, improved NPC naturalness can enhance immersion and replayability, directly impacting game sales and the monetization of virtual experiences. Developers could create characters with richer, more dynamic vocal personalities without the need for extensive, fixed recordings for every possible dialogue line, thereby reducing production costs and accelerating development cycles.
In customer service and contact centers, Realtime TTS-2 could transform interactions with virtual agents. A chatbot or an IVR (interactive voice response) system with an adaptive voice can reduce customer frustration and improve brand perception. This could lead to greater operational efficiency, by allowing AI agents to handle a higher volume of complex interactions more effectively, freeing human staff for higher-value tasks. The adoption of this technology could generate a competitive advantage for companies that implement it, by offering a superior user experience.
Other sectors include advanced virtual assistants, interactive educational applications, and content creation tools. The ability to generate dynamic and contextualized voices opens new avenues for personalization and accessibility. The demand for conversational AI solutions that overcome the limitations of pure text-based systems is increasing, and Realtime TTS-2 positions Inworld AI as a key player in this emerging segment.
Projections and Milestones
The evolution of speech synthesis toward closed-loop and contextually aware models marks a trend toward greater humanization of the AI interface. Realtime TTS-2's performance in real-world scenarios, particularly in latency and the ability to maintain tonal and emotional consistency in prolonged conversations, will be a critical milestone. Adoption by major gaming platforms and customer service companies will validate its impact. This advancement is expected to drive research into multimodal integration, where voice, vision, and other input sensors are combined to create even more sophisticated and perceptive AI agents.
📖 Key Terms Glossary
❓ Frequently Asked Questions
What differentiates Realtime TTS-2 from other speech synthesis models?
Unlike traditional models that rely solely on text transcriptions to generate speech, Realtime TTS-2 processes the full audio context of the conversation in real-time, allowing for dynamic adaptation to the human speaker's style and flow.
What are the main benefits of this technology for AI agents?
The main benefits include greater naturalness and fluidity in the voice of AI agents, resulting in more immersive, less robotic interactions and an improved user experience in conversational applications.
In which sectors is Realtime TTS-2 expected to have the greatest impact?
Significant impact is anticipated in the gaming sector for creating more interactive non-player characters (NPCs), in customer service for more empathetic virtual agents, and in the development of more sophisticated intelligent personal assistants.
Support independent journalism 💸
The crypto ecosystem is volatile. If you decide to invest, do it safely using our affiliate links in the most trusted exchanges. You get a welcome bonus and we get a small commission.
Disclaimer: This content is not financial advice. Do your own research before investing.


